





















Enrich Your Pipedrive Contact Data at Scale: Python Code Tutorial
If you’re working with incomplete contact data in Pipedrive, you’re not alone. Maybe you’ve got a name and a company, but no email. Or a job title but no phone number. It’s frustrating — and worse, it slows down your sales team.
That’s where enrichment comes in. With a simple Python script and Surfe’s Contact Enrichment API, you can turn half-baked CRM entries into fully fleshed-out contact profiles.
In this tutorial, we’ll show you how to build that script step by step — so you can stop guessing and start selling.
By the end, you’ll have a fully working script that:
- Fetches contacts directly from your Pipedrive CRM
- Extracts key information for enrichment
- Sends bulk enrichment requests to Surfe’s Enrichment API
- Retrieves enriched contact data (email addresses and phone numbers)
- Updates your Pipedrive contacts with the enriched data
Ready? Let’s get started.
- Prerequisites
- Setting Up Your Environment
- Creating a Pipedrive service
- Creating a Surfe service
- Putting it all together
- Running the Script
- Final Notes: Credits, Quotas, and Rate Limiting
Want the full script? Jump to the bottom for a quick copy-paste or view it on GitHub!
Prerequisites
- Python 3.x Installation
Most modern operating systems come with Python 3 pre-installed. To check if Python is installed on your system:
- Windows: Open Command Prompt (Win + R, type cmd, press Enter) and run:
py --version
- macOS/Linux: Open Terminal and run:
python3 --version
If Python is not installed, download it from the official Python website and follow the installation instructions for your OS.
- Basic Python Programming Knowledge
- Pipedrive Account with API Access
To fetch and update contacts, you’ll need to store your Pipedrive API token. You can see here how to find it.
- Surfe Account and API Key
To use Surfe’s API, you’ll need to create an account and obtain an API key. You can find the API documentation and instructions for generating your API key in the Surfe Developer Docs.
Step 1: Setting Up Your Environment
Let’s begin by setting up your development environment. We’ll start by creating a virtual environment.
1.1 Creating a Virtual Environment (Optional but Recommended)
Creating a virtual environment is recommended to keep your project dependencies organized:
# macOS/Linux
python3 -m venv env
source env/bin/activate
# Windows
py -m venv env
env\Scripts\activate
1.2 Installing Required Packages
Make sure you have the following Python packages installed:
- requests (for API calls)
- python-dotenv (for storing API keys securely)
# macOS/Linux
python3 -m pip install requests python-dotenv
# Windows
py -m pip install requests python-dotenv
1.3 Storing Your API Keys Securely
It’s best to avoid hardcoding API keys in your script. Instead, store them as environment variables.
- Create a file named .env in your project’s root directory:
PIPEDRIVE_API_KEY
SURFE_API_KEY=your_surfe_api_key
2. Create a Python script file named main.py, add the necessary package imports, and load the API keys:
import os import time import requests from dotenv import load_dotenv # Load environment variables load_dotenv() pipedrive_api_key = os.getenv("PIPEDRIVE_ACCESS_TOKEN") surfe_api_key = os.getenv("SURFE_API_KEY")
Step 2: Creating a Pipedrive service
We will kick off our project by creating a pipedrive service containing a variety of functions and utilities specifically concerned with pipedrive to help us organise and visualize our logic. Here is how we initialize it:
def __init__(self, api_key, api_base_url="https://api.pipedrive.com/api/v2"):
self.api_key = api_key
self.api_base_url = api_base_url
The first component we will build is a method that makes requests to pipedrive API while always adding the the api_token to the query params. this will help us make the following components simpler and avoid repeating the same steps.
def _make_request(self, method, endpoint, params=None, data=None, json_data=None):
url = f"{self.api_base_url}/{endpoint}"
# Ensure api_key is included in all requests
if params is None:
params = {}
params["api_token"] = self.api_key
payload = json.dumps(json_data) if json_data else data if data else None
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
}
response = requests.request(
method=method,
url=url,
params=params,
headers=headers,
data=payload
)
response.raise_for_status()
return response.json()
The next component we will build is a method that fetches a list of all contacts. It sends a GET request to Pipedrive’s Persons API endpoint.
def get_persons(self):
response = self._make_request("GET", "persons", params=params)
if not response.get("success"):
raise Exception(f"Failed to get persons: {response.get('error')}")
return response.get("data", [])
After that we create another method that fetches a contact’s organization, this will be used later to get a contact’s company data which is used as input for enrichment. Note that this step could be avoided if you use v1 (It is deprecated, so use with caution) of the pipedrive API, as it includes organization data by default. that could be useful in specific use-cases where you would like to optimize the amount of network requests you’re making.
def get_organization_by_id(self, org_id):
response = self._make_request("GET", f"organizations/{org_id}")
return response.get("data", {})
Last API method we’re making is the one that updates a person’s data, it works by sending a PATCH request to the /persons/{id} endpoint with the data to update as a json body.
def update_person(self, person_id, update_data):
response = self._make_request("PATCH", f"persons/{person_id}", json_data=update_data)
if not response.get("success"):
raise Exception(f"Failed to update person {person_id}: {response.get('error')}")
return response.get("data", {})
Next, we will create two methods that format inputs for other API requests. The first one is the formatter for the enrichment request we will make to Surfe’s API.
- Takes a list of Pipedrive persons and converts them to a format compatible with Surfe’s API
- For each person, it extracts the essential information (ID, first name, last name)
- Adds company name from the person’s organization if available
- Attempts to extract the company website from email domains
- Only includes a person in the final list if they have sufficient data for enrichment (first+last name AND either company name or website, or linkedinUrl)
- Returns a list of properly formatted people objects ready for Surfe API enrichment
def format_persons_for_surfe(self, persons):
people = []
for person in persons:
# Extract the data from Pipedrive person object
person_data = {
"externalID": str(person["id"]),
"firstName": person.get("first_name", ""),
"lastName": person.get("last_name", ""),
}
# Add company name from organization if available
if person.get("org_id") and isinstance(person["org_id"], dict):
person_data["companyName"] = person["org_id"].get("name", "")
else:
person_data["companyName"] = self.get_organization_by_id(person["org_id"]).get("name", "")
email = next((email["value"] for email in person.get("email", [])
if isinstance(email, dict) and email.get("value")), "")
if email:
email_domain = email.split("@")[-1] if "@" in email else ""
if email_domain:
person_data["companyWebsite"] = email_domain
# Only add if we have enough data to enrich
if ((person_data["firstName"] and person_data["lastName"] and person_data["companyName"]) or
(person_data["firstName"] and person_data["lastName"] and person_data["companyWebsite"])):
people.append(person_data)
return people
The second one is the formatter for the request we will make to update a contact, that we created a method for above (update_person)
- Takes a Pipedrive person ID and enriched data from Surfe
- Finds the specific person in the enriched data by matching the external ID
- Creates an empty update data dictionary for Pipedrive
- Extracts the best email address (prioritizing valid emails) and adds it to the update data
- Extracts the best mobile phone number (prioritizing by confidence score) and adds it to the update data
- Returns the update data if any enrichment was found, or None if no updates are available
- This formatted data is ready to be sent back to Pipedrive’s API to update the person’s record
def prepare_person_update_from_surfe(self, person_id, enriched_data):
# Find the enriched person data by external ID
enriched_person = None
for person in enriched_data.get("people", []):
if person.get("externalID") == str(person_id):
enriched_person = person
break
if not enriched_person:
return None
update_data = {}
# Extract the best email if available
if enriched_person.get("emails"):
# Sort by validation status and take the first one
sorted_emails = sorted(
enriched_person["emails"],
key=lambda x: 0 if x.get("validationStatus") == "VALID" else 1
)
if sorted_emails:
email = sorted_emails[0].get("email")
if email:
update_data["emails"] = [{"value": email, "primary": True}]
# Extract the best mobile phone if available
if enriched_person.get("mobilePhones"):
# Sort by confidence score and take the highest
sorted_phones = sorted(
enriched_person["mobilePhones"],
key=lambda x: x.get("confidenceScore", 0),
reverse=True
)
if sorted_phones:
mobile_phone = sorted_phones[0].get("mobilePhone")
if mobile_phone:
update_data["phones"] = [{"value": mobile_phone, "primary": True}]
return update_data if update_data else NoneStep 3: Creating a Surfe service
Just like Pipedrive, we will create a similar service for Surfe methods that will be used to build this script. This is how we will initialize our service:
def __init__(self, api_key):
self.api_key = api_key
self.base_url = "https://api.surfe.com/v1"
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
First method we will create is one that prepares the payload for calling the Surfe enrichment API
- Takes a list of people data to enrich
- Applies the specified enrichment type (default: emailAndMobile)
- Generates a timestamped list name if none provided
- Returns formatted payload ready for API submission
def prepare_people_payload(self, people_data, enrichment_type="emailAndMobile", list_name=None):
if not list_name:
list_name = f"Enrichment {time.strftime('%Y-%m-%d %H:%M:%S')}"
return {
"enrichmentType": enrichment_type,
"listName": list_name,
"people": people_data
}
t;
Next is a method that Initiates the bulk enrichment process with Surfe API.
- Sends the prepared payload to the bulk enrichment endpoint
- Returns the enrichment ID for status tracking
def start_enrichment(self, payload):
url = f"{self.base_url}/people/enrichments/bulk"
response = requests.post(url, headers=self.headers, json=payload)
response.raise_for_status()
return response.json()["id"]
The last method is one that Monitors the status of an enrichment request until completion or failure.
- Repeatedly checks the enrichment status at defined intervals
- Returns enrichment results when status is “COMPLETED”
- Raises exception if enrichment fails or times out
- Configurable with max attempts and delay between checks
def poll_enrichment_status(self, enrichment_id, max_attempts=60, delay=5):
url = f"{self.base_url}/people/enrichments/bulk/{enrichment_id}"
attempts = 0
while attempts < max_attempts:
response = requests.get(url, headers=self.headers)
response.raise_for_status()
data = response.json()
status = data.get("status")
if status == "COMPLETED":
return data
elif status == "FAILED":
raise Exception(f"Enrichment failed: {data.get('error', 'Unknown error')}")
print(f"Enrichment status: {status}. Waiting {delay} seconds...")
time.sleep(delay)
attempts += 1
raise Exception("Enrichment timed out")Step 4: Putting it all together
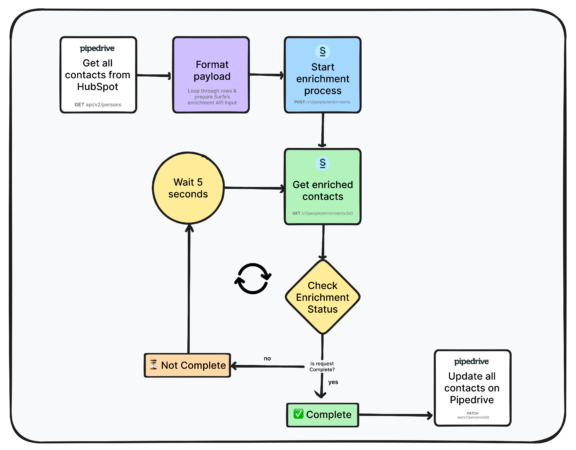
Now it is time to start putting together all the components we just created to build the full script. This main function orchestrates the entire Pipedrive contact enrichment process:
- Loads environment variables and checks for required API keys
- Initializes both Pipedrive and Surfe services
- Fetches persons from Pipedrive with a limit of 100 records
- Formats the Pipedrive persons into a structure compatible with Surfe API
- Prepares the enrichment payload with a timestamped list name
- Starts the enrichment process and retrieves the enrichment ID
- Polls for enrichment completion, waiting for results
- Updates each Pipedrive person with their enriched data:
- Processes each person individually
- Prepares update data based on enrichment results
- Sends updates back to Pipedrive
- Provides progress feedback throughout the process
- Handles exceptions with appropriate error messaging
The following illustration helps explain better what the flow looks like
def main():
"""
Main function to orchestrate the enrichment process
"""
load_dotenv()
pipedrive_api_key = os.getenv("PIPEDRIVE_API_KEY")
surfe_api_key = os.getenv("SURFE_API_KEY")
if not pipedrive_api_key or not surfe_api_key:
print("Error: Missing API keys. Please check your .env file.")
return
try:
# Initialize the Pipedrive and Surfe services
pipedrive_service = PipedriveService(pipedrive_api_key)
surfe_service = SurfeService(surfe_api_key)
# Step 1: Get persons from Pipedrive
print("Fetching persons from Pipedrive...")
persons = pipedrive_service.get_persons(
limit=100,
)
print(f"Found {len(persons)} persons to enrich")
if not persons:
print("No persons found that need enrichment")
return
# Step 2: Format persons for Surfe API
print("Preparing data for Surfe enrichment...")
people_data = pipedrive_service.format_persons_for_surfe(persons)
if not people_data:
print("No persons with sufficient data for enrichment")
return
print(f"Prepared {len(people_data)} persons for enrichment")
# Step 3: Prepare and start enrichment process
surfe_payload = surfe_service.prepare_people_payload(
people_data,
list_name=f"Pipedrive Enrichment {time.strftime('%Y-%m-%d %H:%M:%S')}"
)
print("Starting Surfe enrichment process...")
enrichment_id = surfe_service.start_enrichment(surfe_payload)
print(f"Enrichment started with ID: {enrichment_id}")
# Step 4: Poll for results
print("Polling for enrichment results...")
enriched_data = surfe_service.poll_enrichment_status(enrichment_id)
print("Enrichment completed successfully")
print(f"Enriched {len(enriched_data.get('people', []))} persons")
# Step 5: Update Pipedrive persons with enriched data
print("Updating persons in Pipedrive...")
updated_count = 0
for person in persons:
person_id = person["id"]
update_data = pipedrive_service.prepare_person_update_from_surfe(person_id, enriched_data)
if update_data:
print(f"Updating person {person_id}...")
pipedrive_service.update_person(person_id, update_data)
updated_count += 1
print(f"Successfully updated {updated_count} persons in Pipedrive")
except Exception as e:
print(f"Error: {str(e)}")
Step 5: Running the Script
Now that you have your complete script, It is time to run it and watch the magic happen! Here’s how to execute the script and what to expect during its operation.
- Ensure your .env file contains your Surfe API key and your Pipedrive API token:
PIPEDRIVE_API_KEY=your_pipedrive_access_token
SURFE_API_KEY=your_surfe_api_key_here
- Open your terminal or command prompt, navigate to the directory containing your script, and run:
python main.pyExpected Output
When you run the script, you will see a series of status messages in the console that help you track its progress:

Complete Code for Easy Integration
"""
Pipedrive Contact Enrichment Script
This script fetches persons from Pipedrive, enriches them using Surfe API,
and updates the Pipedrive persons with the enriched data.
"""
import os
import sys
import time
from dotenv import load_dotenv
# Add core directory to path
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '../../')))
# Import core services
from core.surfe import SurfeService
from core.integrations.pipedrive import PipedriveService
def main():
"""
Main function to orchestrate the enrichment process
"""
load_dotenv()
pipedrive_api_key = os.getenv("PIPEDRIVE_API_KEY")
surfe_api_key = os.getenv("SURFE_API_KEY")
if not pipedrive_api_key or not surfe_api_key:
print("Error: Missing API keys. Please check your .env file.")
return
try:
# Initialize the Pipedrive and Surfe services
pipedrive_service = PipedriveService(pipedrive_api_key)
surfe_service = SurfeService(surfe_api_key)
# Step 1: Get persons from Pipedrive
print("Fetching persons from Pipedrive...")
persons = pipedrive_service.get_persons(
limit=100,
)
print(f"Found {len(persons)} persons to enrich")
if not persons:
print("No persons found that need enrichment")
return
# Step 2: Format persons for Surfe API
print("Preparing data for Surfe enrichment...")
people_data = pipedrive_service.format_persons_for_surfe(persons)
if not people_data:
print("No persons with sufficient data for enrichment")
return
print(f"Prepared {len(people_data)} persons for enrichment")
# Step 3: Prepare and start enrichment process
surfe_payload = surfe_service.prepare_people_payload(
people_data,
list_name=f"Pipedrive Enrichment {time.strftime('%Y-%m-%d %H:%M:%S')}"
)
print("Starting Surfe enrichment process...")
enrichment_id = surfe_service.start_enrichment(surfe_payload)
print(f"Enrichment started with ID: {enrichment_id}")
# Step 4: Poll for results
print("Polling for enrichment results...")
enriched_data = surfe_service.poll_enrichment_status(enrichment_id)
print("Enrichment completed successfully")
print(f"Enriched {len(enriched_data.get('people', []))} persons")
# Step 5: Update Pipedrive persons with enriched data
print("Updating persons in Pipedrive...")
updated_count = 0
for person in persons:
person_id = person["id"]
update_data = pipedrive_service.prepare_person_update_from_surfe(person_id, enriched_data)
if update_data:
print(f"Updating person {person_id}...")
pipedrive_service.update_person(person_id, update_data)
updated_count += 1
print(f"Successfully updated {updated_count} persons in Pipedrive")
except Exception as e:
print(f"Error: {str(e)}")
if __name__ == "__main__":
main()
Final Notes: Credits, Quotas, and Rate Limiting
Credits & Quotas
Surfe’s API uses a credit system for people enrichment. Retrieving email, landline, and job details consumes email credits, while retrieving mobile phone numbers consumes mobile credits. There are also daily quotas, such as 2,000 people enrichments per day and 200 organization look-alike searches per day. For more information on credits and quotas, please speak to a Surfe representative to discuss a tailored plan that works for you and your business needs. Quotas reset at midnight (local time), and additional credits can be purchased if needed. For full details, refer to the Credits & Quotas documentation.
Rate Limiting
Surfe enforces rate limits to ensure fair API usage. Users can make up to 10 requests per second, with short bursts of up to 20 requests allowed. The limit resets every minute. Exceeding this results in a 429 Too Many Requests error, so it’s recommended to implement retries in case of rate limit issues. Learn more in the Rate Limits documentation.

Ready to enrich your contacts and accelerate your sales process?
Give Surfe a go and make sure your team never wastes time on bad data again.
Contact Enrichment API FAQs
What Is a Contact Enrichment API?
A contact enrichment API is a tool that fills in the gaps in your CRM data by adding missing contact details — like job title, seniority, company website, email address, and phone number. For sales teams, this means no more guessing who to reach out to or wasting time manually researching leads. Instead, you get complete, up-to-date contact profiles delivered straight into your CRM.
Why Do Sales Teams Need a Contact Enrichment API?
Sales teams move fast — but incomplete data slows everything down. A contact enrichment API helps you quickly identify high-value leads, prioritize outreach, and personalize your messaging. Instead of cold emails to “info@” addresses, you get verified contact info that helps you land in the right inbox, every time.
What’s the Difference Between a Contact Enrichment API and Other Data Tools?
Most traditional data tools require manual CSV uploads, long setup times, or separate platforms to search for leads. A contact enrichment API plugs directly into your workflow. It works with your CRM (like Pipedrive) and enriches contact data programmatically — so you don’t need to copy, paste, or switch tabs to get the info you need.
How Does Surfe’s Contact Enrichment API Work with Pipedrive?
Surfe’s Contact Enrichment API doesn’t connect to Pipedrive out of the box — but that’s what this tutorial is for. With a custom Python script, you can pull contacts from Pipedrive, send them to Surfe for enrichment, and update your CRM with enriched data like email addresses, phone numbers, and job titles — all in one smooth workflow.
What Data Can I Enrich with Surfe’s API?
Surfe’s API can return:
-
Verified email addresses (work and personal)
-
Mobile and landline numbers
-
Job titles and seniority
-
Company name and website
-
Location and department
-
Social profiles (LinkedIn, Meta, X, etc.)
The more input data you provide (like full name + company), the better the results.
Do I Need a Developer to Use the API?
Not necessarily. If you’re comfortable running basic Python scripts, you can follow this guide and set it up yourself — no full dev team required. And if you get stuck, tools like ChatGPT can help generate or fix the code.
How Often Can I Run the Enrichment Script?
You can run it as often as your workflow requires — once a day, once a week, or whenever new contacts are added to Pipedrive. Just be mindful of your API usage and credit limits depending on your Surfe plan.
Can I Combine Surfe’s API with Other Tools?
Yes! Once you’ve enriched your contacts, you can push that data into your email platform, sales engagement tool, or even trigger workflows using tools like Zapier. It’s flexible, scalable, and works with whatever your stack looks like.
